O idioma, que é falado na região amazônica do Brasil e da Colômbia, está em risco de extinção. A iniciativa pode ajudar a reverter esse processo
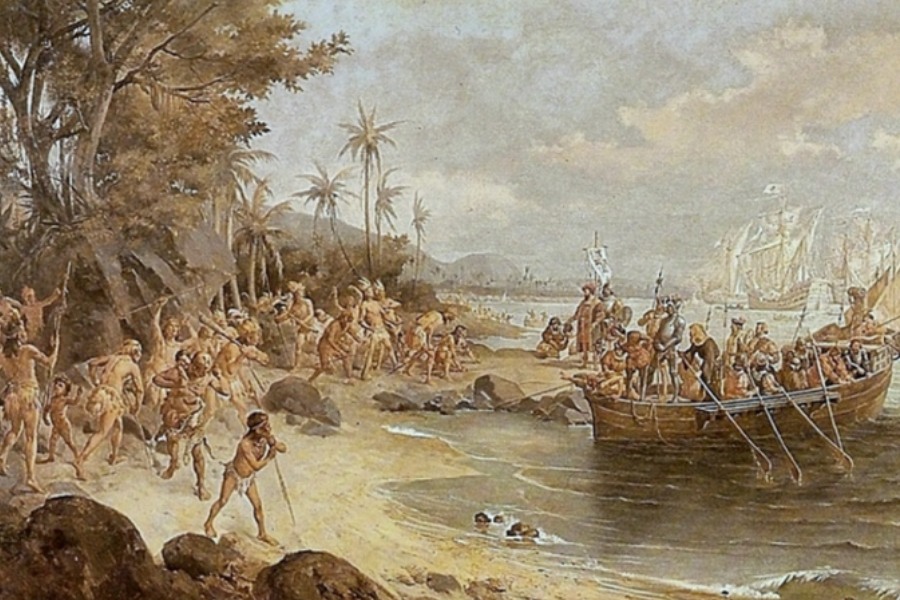
Desembarque de Pedro Álvares Cabral, de Oscar Pereira da Silva: língua foi adotada pelos portugueses para comunicação com povos indígenas
Por Sérgio de Sousa
Da Agência UFC
Fortaleza – CE. Conhecida como Nheengatu, a Língua Geral Amazônica (LGA) é a única língua viva descendente do Tupi antigo. Contudo, com apenas 6 mil falantes no Brasil e 8 mil na Colômbia, conforme a edição de 2022 do catálogo de línguas Ethnologue, do Summer Institute of Linguistics (SIL), o idioma se encontra em risco de extinção. Em um esforço de preservar a memória e ampliar o conhecimento sobre esse Tupi moderno, o grupo de pesquisa Computação e Linguagem Natural (Complin) da Universidade Federal do Ceará (UFC) vem criando uma série de ferramentas computacionais para o processamento do Nheengatu, o que vem permitindo a investigação de sua estrutura gramatical e ampliando as possibilidades de tradução.
Antes falado também na Venezuela, o Nheengatu já estaria, conforme o Ethnologue, praticamente extinto naquele país. Já no Brasil e na Colômbia, o processo de transmissão da língua às crianças vem sendo interrompido, de acordo com dados da mesma fonte. “Ou seja, mais e mais crianças estariam deixando de aprendê-la, adotando, no Brasil, o Português e, na Colômbia, o Tucano”, aponta o professor Leonel Figueiredo de Alencar Araripe, do Programa de Pós-Graduação em Linguística e criador do Complin.
Considera este conteúdo relevante? Apoie a Eco Nordeste e fortaleça o jornalismo de soluções independente e colaborativo!
Em 2009, ele criou o grupo, que, entre suas linhas de pesquisa, dedica-se à Linguística Computacional. Subdisciplina da Linguística, ela visa construir modelos computacionais do funcionamento das línguas naturais, que são aquelas desenvolvidas naturalmente pelo ser humano. “Desse modo, o linguista passa a ser também um programador, elaborando algoritmos numa linguagem de programação ou especificações formais numa linguagem matemática para o processamento da língua nos diferentes níveis de descrição, ou seja, no nível fonético, morfológico, sintático, semântico e pragmático-discursivo”, explica o professor.

O professor Leonel Araripe é o líder do grupo de pesquisa Computação e Linguagem Natural (Complin), que está criando as ferramentas para o Nheengatu | Foto: Ribamar Neto/UFC
Focado anteriormente em ferramentas para o Português, o grupo começou, há três anos, a aplicar esses estudos à Língua Geral Amazônica. De acordo com o pesquisador, apesar de sua importância histórica, cultural e linguística, ainda não havia nada em termos de ferramentas e recursos para o processamento computacional da LGA. Daí, em 2019, o pesquisador deu os primeiros passos de um projeto que pretende permitir a tradução automática entre o Nheengatu e diversas outras línguas.
O tradutor de Nheengatu
A primeira ferramenta criada foi o GrammYEP, o tradutor automático pioneiro em uma língua indígena brasileira. Concluída em 2020, essa gramática computacional traduz textos simples com sentenças que expressam qualidades, estados e localizações de pessoas e objetos que levam em conta os padrões gramaticais e a semântica (isto é, o significado das palavras e frases) do Tupi moderno.
O tradutor, no momento, tem dupla vocação. Por ser capaz de traduzir da LGA para o Inglês e o Português e ainda de fazer o trabalho inverso, ele pode ser usado no aprendizado da LGA por falantes de Português ou Inglês, ou no aprendizado do Português e do Inglês por falantes da LGA. O funcionamento do GrammYEP é explicado no artigo “Uma gramática computacional de um fragmento do Nheengatu”, publicado na Revista de Estudos da Linguagem, da Universidade Federal de Minas Gerais (UFMG).
Agora, o professor Leonel Araripe trabalha na ampliação dessa gramática, em parceria com a cientista da computação finlandesa Inari Listenmaa, ligada ao Centro de Direito Computacional da Universidade de Administração de Singapura. A nova versão tem o objetivo de permitir a tradução entre a LGA e um grupo de mais de 30 línguas.
O GrammYEP utilizou como base para sua elaboração trabalhos acadêmicos que traziam dados obtidos na literatura ou em campo, especialmente na região do Alto Rio Negro, no município de São Gabriel da Cachoeira, no Amazonas. Entretanto, ao longo do processo de modelação matemática da língua, o pesquisador se deparou com um problema: os dados dos trabalhos que serviram de fonte para o tradutor não traziam os termos das sentenças organizados em classes gramaticais de palavras (como verbos, substantivos, adjetivos etc), nem indicavam sua função sintática (como sujeito, predicado, complementos verbais e nominais etc.). Essa ausência complica a comprovação das formulações computacionais feitas pelo GrammYEP. A partir daí, ele partiu para uma nova empreitada.
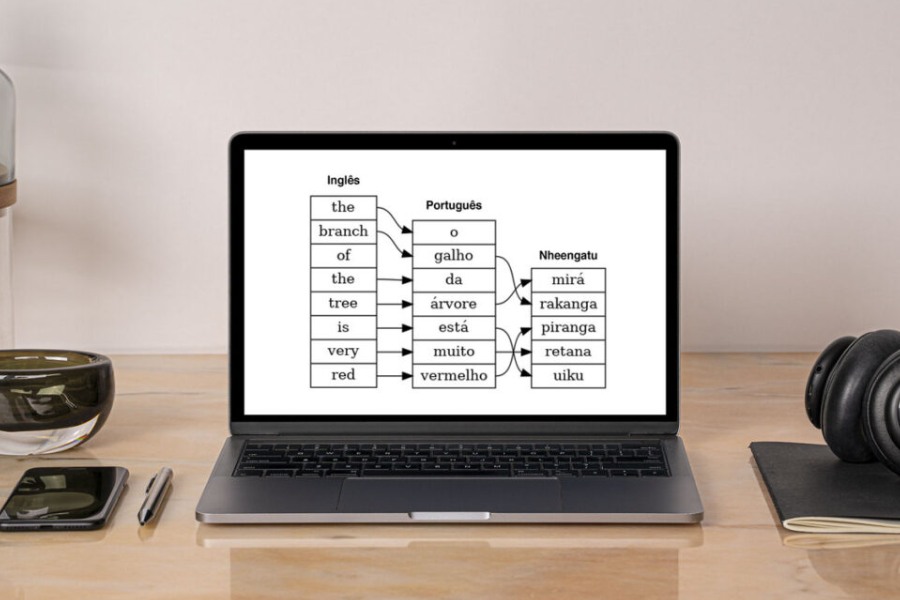
GrammYEP: exemplo de tradução automática entre Inglês, Português e Nheengatu
O Nheentiquetador
A ideia, então, foi criar um etiquetador morfossintático do Nheengatu, o qual recebeu o nome de Nheentiquetador. A ferramenta, que é um pré-requisito para a investigação da estrutura gramatical da língua, tem a função de atribuir, a cada palavra de uma frase, a sua classe gramatical.
O projeto foi realizado com participação da aluna de graduação Dominick Maia Alexandre, que apresentou em 2021 o trabalho “Nheentiquetador: um etiquetador morfossintático para o sintagma nominal do Nheengatu” no XL Encontro de Iniciação Científica da UFC, sendo ao final contemplada com o Prêmio UFC, Ciência e Sociedade, na categoria Pesquisa. O trabalho contou também com a contribuição de Juliana Gurgel, orientanda de mestrado do professor.
Como informa o nome do projeto, a pesquisa inicial concentrava-se no chamado sintagma nominal da língua, ou seja, nas unidades constituintes de uma sentença compostas por nomes ou pronomes. Já os chamados sintagmas verbais serão objeto da continuação do projeto, a cargo de Juliana Gurgel, cuja dissertação, que deve ser concluída até o fim do ano, propõe-se a ampliar esse etiquetador inicial. A conclusão deste trabalho, informa o professor, irá facilitar o estudo do idioma e a elaboração de materiais didáticos.
Um etiquetador morfossintático atua também na resolução das ambiguidades das palavras com base no contexto. “Por exemplo, uma sentença como ‘Quem casa quer casa.’, analisada por um etiquetador, produz como resultado ‘quem/PRONOME casa/VERBO quer/VERBO casa/SUBSTANTIVO ./PONTUAÇÃO’, em que as duas ocorrências da forma ambígua ‘casa’ são identificadas como verbo e substantivo, respectivamente. As etiquetas podem ser mais complexas, ao identificar, por exemplo, o tempo e o modo verbal etc”, elucida.
Até o momento, informa o professor, não existe nenhuma língua indígena brasileira que disponha de uma anotação morfossintática automática, diferentemente das chamadas línguas majoritárias, como o Português, que já contam com etiquetadores computacionais. O Nheentiquetador, então, passa a disponibilizar às comunidades de desenvolvedores e de pesquisadores esse etiquetador sob licença gratuita, por meio de software livre.
Segundo Araripe, o etiquetador, após concluída sua expansão por meio da dissertação de Juliana Gurgel, poderá alcançar uma acurácia capaz de classificar inclusive palavras novas, que não constam no dicionário. “Um algoritmo de aprendizagem de máquina automaticamente constrói um modelo estatístico da língua, com base no qual pode fazer essa ‘adivinhação’ de palavras desconhecidas, levando em conta a probabilidade da palavra em questão ser de uma determinada classe, dado o contexto precedente ou dada a forma da palavra”, esclarece.
O etiquetador, contudo, limita-se à classificação das palavras e dos sinais de pontuação. Já a tarefa de especificar qual função as palavras ocupam na frase ficará a cargo de um outro projeto que começará a ser desenvolvido em agosto deste ano. Com previsão de conclusão em julho de 2023, será elaborado então um analisador sintático automático, que completará essa atribuição não cumprida pelo etiquetador. Para isso, o professor Leonel Araripe contará com a colaboração do cientista da computação Alexandre Rademaker, vice-líder do (Complin), pesquisador da IBM Research e professor da Escola de Matemática Aplicada da Fundação Getúlio Vargas (FGV), no Rio de Janeiro.
Todos esses projetos, acredita o pesquisador, permitirão que a língua passe a ser conhecida e compreendida por um universo cada vez maior de pessoas, afastando assim o Nheengatu do risco de extinção.
“Para preservação de uma língua minoritária, considero importante não só que falantes nativos a utilizem no cotidiano e a transmitam aos filhos, mas também que pesquisadores e estudantes de diferentes áreas, pessoas apaixonadas por idiomas e curiosos diversos a aprendam e a cultivem. De fato, amplia-se com isso enormemente o círculo de potenciais contribuidores para divulgação do idioma”, defende o pesquisador.
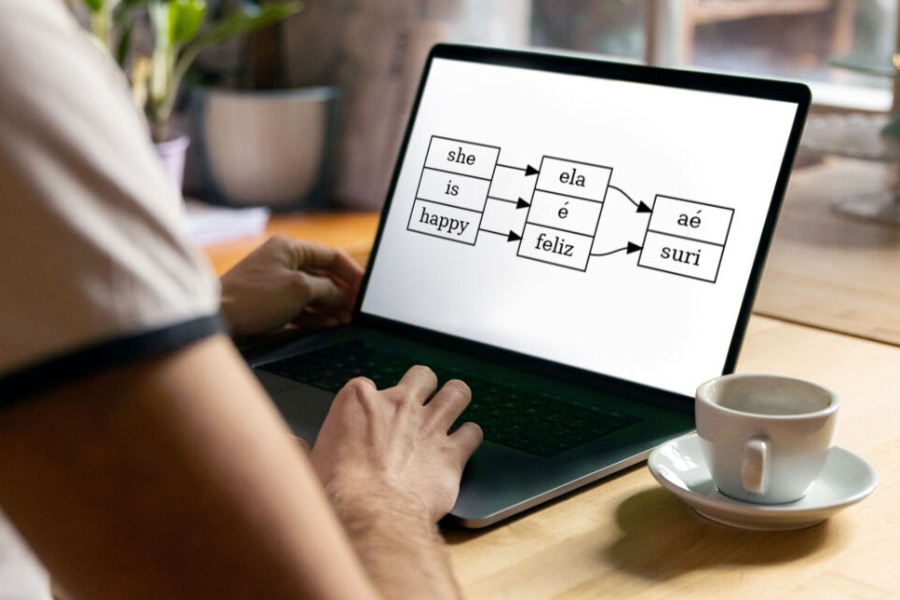
Inglês-Português-Nheengatu: ferramenta é o primeiro tradutor automático de uma língua indígena brasileira
Uma língua acima das etnias
As línguas indígenas brasileiras não possuem vinculação genética com nenhum outro tronco linguístico fora das Américas, o que torna o trabalho de tradução desses idiomas ainda mais complexo. No caso do Nheengatu, por exemplo, os pronomes pessoais não distinguem o gênero da pessoa ou objeto a que se referem, o que é uma característica das línguas da família Tupi-Guarani. Com isso, não há como fazer uma tradução correta sem saber a quem o falante se refere. “Não há, por exemplo, como sistemas como o do Google identificar o gênero desse referente numa situação de comunicação face a face, em que o falante está apontando para alguém”, avalia o professor Leonel Araripe.
A motivação do professor para esta pesquisa tem raízes histórico-afetivas. O seu sobrenome, Araripe, foi adotado pelos seus antepassados portugueses em substituição a Pereira. Araripe tem origem Tupi, a única língua indígena brasileira que foi documentada em seus vários estágios de evolução desde o século XVI. O Nheengatu, ressalta, foi o idioma adotado pelos portugueses para comunicação, dada a grande diversidade de línguas existentes. “Eles optaram por ela pelo fato de ela ser ‘a língua mais falada na costa do Brasil’, como consta no título da gramática de padre Anchieta, publicada em 1595”, explica Araripe.
Ele ressalta que o Nheengatu é a única supra étnica no quadro de línguas indígenas brasileiras ainda vivas. “Nunca foi a língua de uma etnia específica. Foi a língua da sociedade cabocla do Maranhão e Grão-Pará, falada por portugueses, seus descendentes, povos indígenas de diferentes etnias etc., tornada oficial pela Carta Régia de 1689, status que manteve até 1727, quando outra Carta Régia a proibiu, o que não impediu que continuasse como língua da maior parte da população até meados do século XIX”, rememora o pesquisador.
Não existe nem jamais existiu um povo Nheengatu. O termo foi cunhado no século XIX, significando “língua boa”. “Na época, ainda se usava o termo ‘Brasílica’ para designar a LGA. Até 1877, a LGA era mais falada que o Português em toda a região amazônica. A partir daí, começou o seu declínio, recuando progressivamente Amazônia adentro”, informa.
Segundo o professor, a literatura sobre o assunto afirma que o enfraquecimento da língua na região se deu sobretudo pela massiva migração nordestina a partir de 1877. Fugindo da seca, cerca de 500 mil migrantes que apenas falavam Português partiram rumo ao Norte para aproveitar o ciclo da borracha. Hoje, o “último refúgio” da LGA é a região do Alto Rio Negro, que abrange o território do Brasil e da Colômbia.
O Nheengatu, diferentemente do que se chegou a pensar, não foi inventado pelos jesuítas, nem é produto de uma mistura com o Português. “Ele é resultado de uma evolução gradual do Tupi antigo (Tupinambá), ao longo de 500 anos de história. Conhecê-lo abre uma porta de acesso ao aprendizado do Tupi antigo e à sua rica literatura e permite entender a formação de milhares de palavras do português do Brasil”, reforça.


